A Data Plane Emulation and Hardware-Software Co-Design Enabling Platform for AI and High-Performance Storage
🚀 Project Tensorplane AI Foundry While the underlying C++ engine in this repository is
dataplane-emu, this project serves as the foundation for the Tensorplane AI Foundry—an end-to-end, zero-copy architecture designed for hyperscaler I/O offloading and autonomous Agentic AI orchestration.
Watch the demo showcasing high-performance storage emulation, lock-free SPDK queues, and multi-cloud benchmarking on AWS Graviton3 and Azure Cobalt 100.
The Mission: To enable enterprise AI and HPC data centers to achieve the extreme efficiency and performance of tier-one hyperscalers. As datasets grow and AI models scale into the trillions of parameters, traditional operating systems create an I/O bottleneck that starves expensive GPUs of data.
By leveraging hardware-software co-design—specifically zero-copy data planes, kernel-bypassing architectures like SPDK, and DPU/SmartNIC offloading—Tensorplane (operating as dataplane-emu) streams massive training datasets directly from storage fabrics into GPU memory without CPU bounce-buffer overhead. This approach democratizes hyperscaler-grade hardware acceleration for the enterprise, slashing Total Cost of Ownership (TCO) while delivering the bare-metal, microsecond-latency infrastructure required to power next-generation agentic AI and high-performance computing workloads.
At its core, dataplane-emu is designed to be the "QEMU for Data Planes," acting as a deterministic sandbox for testing these next-generation, kernel-bypassing architectures before production deployment.
We have separated our documentation to serve both enterprise architects and systems engineers.
High-level architectural documentation detailing our approach to AI training bottlenecks and autonomous orchestration.
- Vision & Architecture Manifesto: The "0-Kernel, 0-Copy, Hardware-Enlightened" data plane thesis.
- Agentic Architecture & MCP: How we use the Model Context Protocol and a Mixture-of-Experts (MoE) to achieve recursive self-improvement and autonomous kernel optimization.
- Agent Customization Change Control: The required update-review-approval flow for agent, prompt, instruction, and hook changes before merge to
main.
Private agent definitions can remain in a private repository and still be loaded locally in this workspace:
- Clone your private customization repository (default expected path:
$HOME/copilot-customizations). - Run
bash scripts/agents/sync-private-agents.shto copypersonal/agents/*.agent.mdinto.github/agents/locally. - Keep those private files out of public tracking by using local excludes (
.git/info/exclude) or by keeping them only in the private repo.
Low-level microarchitectural documentation detailing the C++/Rust kernel-bypass implementation.
- POSIX Interception Bridge:
LD_PRELOADtrampolines, Fake FDs, and transparent legacy application support. - Lock-Free SPDK Queues: ARM64 LSE atomics, memory barriers (
dsb st), and zero-copy shared memory (Iov/Ior).
Published research laying the foundational proof-of-concept architectures for our bypass routing.
- Eliminating the OS Kernel (.pdf): The primary research paper outlining kernel-bypass mechanics.
- Publications Index: Associated proofs and dataset references.
- 100% Lock-Free Synchronization: Elimination of
std::mutexin favor of C++11/Rust atomic memory orderings (Acquire/Release semantics) to prevent thread contention. - Architecture Modeling: Designed to simulate different hardware memory models (TSO vs. Weak Ordering) during I/O transfer. It models architecture-specific microarchitectural hazards, such as utilizing explicit
DSBbarriers on ARM64 Graviton instances, andFENCEinstructions on RISC-V (RVWMO). - POSIX Interceptor (FUSE/LD_PRELOAD): A high-performance bridge allowing standard Linux tools (
ls,dd,fio) and legacy databases to communicate directly with user-space storage queues without code modification.
Tensorplane and dataplane-emu do not exist in a vacuum. Our architecture is deeply informed by and builds upon the following state-of-the-art systems, research, and protocols:
- DeepSeek 3FS (Fire-Flyer File System): We heavily drew inspiration from 3FS's
USRBIOAPI, specifically its use of shared memory I/O Vectors (Iov) and I/O Rings (Ior) to achieve extreme-throughput, zero-copy data ingestion for AI training dataloaders. - Intel DAOS (Distributed Asynchronous Object Storage): Our Phase 4 POSIX interception bridge models the
libpil4dfsapproach, utilizingLD_PRELOADto grant legacy applications transparent access to user-space storage fabrics without modifying source code. - XRP (In-Kernel Storage Functions with eBPF): Our hardware-enlightened execution path leverages the XRP paradigm to push computation (like B-Tree index lookups) all the way down into the NVMe driver's interrupt handler via eBPF.
- SPDK (Storage Performance Development Kit): The core engine of our data plane relies on SPDK-style lock-free submission and completion queues, polling at 100% CPU utilization to entirely eliminate the Linux kernel context-switch tax.
- zIO (Transparent Zero-Copy I/O): We utilize
userfaultfdmemory tracking principles from zIO to leave intermediate memory buffers unmapped, transparently eliminating user-space memory copies. - Anthropic Model Context Protocol (MCP): Our Multi-Agent System (MAS) orchestration layer uses MCP to standardize the interface between our AI reasoning engines, telemetry tools, and autonomous kernel compilers.
- SGLang (RadixAttention) & vLLM: For our serving infrastructure design, we target advanced KV cache management techniques like Radix Trees to enable cross-request prompt sharing, drastically accelerating agentic AI workflows.
- Alibaba PolarFS: For its compute-storage decoupling and user-space file system designed to provide ultra-low latency for cloud databases.
- pulp-platform/mempool: For pioneering research in mapping OS-level synchronization primitives and message queues directly into tightly-coupled RISC-V hardware accelerators and shared L1 memory clusters.
Leverages the Storage Performance Development Kit (SPDK) to unbind PCIe NVMe controllers from native kernel drivers and bind them to user-space vfio-pci drivers. Creates an NVMe over Fabrics (NVMe-oF) TCP loopback target to disaggregate the storage plane for AI-scale workloads.
Implements pure C++/Rust Single-Producer Single-Consumer (SPSC) ring buffers. This phase tames weakly-ordered memory models (ARM64/RVWMO) by:
- Eliminating False Sharing: Forcing
alignas(64)on atomic tail pointers. - Hardware-Assisted Polling: Utilizing the RISC-V
Zawrs(Wait-on-Reservation-Set) extension to replace power-hungry spin-loops with energy-efficient polling. - Cache Pollution Mitigation: Utilizing the RISC-V
Zihintntlextension (Non-Temporal Locality Hints) to prevent ephemeral message-passing data from polluting the L1 cache.
Engineers an automated, architecture-agnostic AWS Graviton3 (ARM64) environment via Terraform and cloud-init. This securely isolates the developer OS on persistent EBS volumes while dedicating raw ephemeral NVMe block access exclusively to the user-space SPDK drivers. It includes automated zero-touch hugepage allocation (2MB/1GB) for Direct Memory Access (DMA).
A user-space file system virtual bridge utilizing FUSE to gracefully route storage interactions from legacy applications directly into the lock-free SPDK queues. While it officially establishes kernel-bypass routing without requiring application source code modifications, it still fundamentally incurs standard Linux VFS context-switching limits.
To accelerate unmodified legacy applications (e.g., PostgreSQL) without requiring source code rewrites, dataplane-emu implements a transparent system call interception bridge.
- Dynamic Linker Hooking: Utilizing
LD_PRELOAD, we inject a custom shared library that overrides standardglibcI/O symbols (e.g.,pread,pwrite). - User-Space Routing: Intercepted I/O requests targeting our storage volumes are routed directly into our zero-copy, lock-free SPDK queues, completely bypassing the Linux Virtual File System (VFS) and the "20,000-instruction kernel tax."
- Industry Alignment: This trampoline-based interception architecture mirrors the high-throughput design patterns of modern AI file systems, such as the DAOS
libpil4dfslibrary. - Limitations: This fast-path routing requires dynamically linked executables. Statically linked binaries or applications invoking raw inline
syscallinstructions will bypass the hook and fall back to standard kernel I/O.
Moving beyond user-space POSIX interception, the final phase pushes storage computation directly to the hardware boundaries to support legacy databases and IO-intensive AI workloads:
- In-Kernel eBPF Offloading (XRP): Implementing the eXpress Resubmission Path (XRP) by hooking an eBPF parser directly into the NVMe driver's completion interrupt handler [1]. This completely bypasses the block, file system, and system call layers, allowing the NVMe interrupt handler to instantly construct and resubmit dependent storage requests (like B-Tree lookups), moving computation closer to the storage device [2].
- Transparent Zero-Copy I/O (zIO): Eliminating memory copies between kernel-bypass networking (DPDK) and storage stacks (SPDK) [3]. Leveraging
userfaultfdto intercept application memory access, this dynamically maps and resolves intermediate buffers to eliminate CPU copy overheads without requiring developers to rewrite their applications [4].
The ultimate capstone of dataplane-emu is providing seamless, zero-modification acceleration for legacy applications (e.g., PostgreSQL, Redis, MongoDB) and legacy file systems. This phase integrates our kernel-bypass and hardware-offloading primitives into transparent infrastructure layers:
- User-Space Block Devices (
ublk): Exposing lock-free user-space SPDK queues as standard Linux block devices via theio_uring-basedublkframework. This allows legacy file systems (ext4, XFS) to operate transparently on top of an extreme-throughput, kernel-bypassed NVMe storage engine. - SmartNIC / DPU Offloading: Relocating the POSIX-compatible client data plane entirely onto a Data Processing Unit (e.g., NVIDIA BlueField-3). This presents a standard interface to the host CPU while executing all RDMA and NVMe-oF networking transparently on the NIC's embedded ARM cores, achieving multi-tenant isolation and host-CPU relief.
- Transparent Zero-Copy Memory Tracking (zIO): Utilizing page-fault interception to track data flows within legacy applications. By unmapping intermediate buffers, we can transparently eliminate unnecessary application-level data copies and achieve optimistic end-to-end network-to-storage persistence without modifying application source code.
- Hardware-Assisted OS Services (RISC-V): Emulating RISC-V hardware accelerators (inspired by the ChamelIoT framework) that transparently replace software-based OS kernel services (scheduling, IPC) at compile time, achieving drastic latency reduction for unmodified legacy software.
To empirically prove the performance gains of our kernel-bypass architecture on AWS Graviton3 (Neoverse-V1) and Azure Cobalt 100 (Neoverse-N2), we utilize a deterministic three-stage benchmark comparing kernel fio, user-space FUSE bridge, and real SPDK bdevperf bypass (cloud-aware: vfio-pci on AWS Nitro, bdev_uring on Azure Boost) at multiple queue depths (QD=1, QD=16, QD=128).
By sweeping queue depths from latency-sensitive (QD=1) through knee-of-curve (QD=16) to throughput-saturating (QD=128) with 4K mixed random reads/writes, the benchmark demonstrates:
- Zero-Copy DMA: Complete evasion of the Linux VFS and block layer overhead.
- Lock-Free Contention Resolution: The ability of Neoverse-N2 Large System Extensions (LSE) atomics to sustain extreme queue contention without POSIX mutex degradation.
- Compute Isolation: Saturating the local NVMe drive using only a single physical core, leaving the remaining cluster topology entirely free for compute-heavy AI workloads.
To achieve true zero-copy I/O and maximize throughput on modern cloud silicon, dataplane-emu is heavily optimized for the AWS Graviton3 (Neoverse-V1), AWS Graviton4 (Neoverse-V2), and Azure Cobalt 100 (Neoverse-N2) architectures.
- Large System Extensions (LSE): We bypass traditional, heavily contended x86 locks by compiling with
-mcpu=neoverse-v1 -moutline-atomics(Graviton3) or-mcpu=neoverse-v2(Graviton4/Cobalt 100). This forces the binary to utilize hardware-accelerated LSE atomics (CASAL/LDADD) for our submission and completion queues. - Strict Memory Semantics: Because ARM64 uses a weakly ordered memory model, all lock-free SPDK ring buffers enforce strict
std::memory_order_acquireandstd::memory_order_releasesemantics to prevent microarchitectural hazards. - 1:1 Physical Core Pinning (No SMT): Arm Neoverse maps vCPUs directly to physical cores. We pin our DPDK-style polling threads directly to these cores (
--core-mask), guaranteeing zero performance jitter from shared execution resources. - SVE2 & NEON Vectorization: Bulk data transformations and checksums are auto-vectorized using the Scalable Vector Extension 2 (SVE2), massively outperforming legacy x86 instruction-level parallelism.
To overcome local hardware bottlenecks and secure the code execution environment, dataplane-emu agents leverage the open-source Google Colab MCP Server as their primary execution sandbox [5].
- Cloud-Native Prototyping: Instead of running an autonomous agent's generated code directly on local hardware—which might not be ideal for security or performance—agents connect to Colab's cloud environment, utilizing it as a fast, secure sandbox with powerful compute capabilities [5].
- Full Lifecycle Automation: Our control plane agents can programmatically control the Colab notebook interface to automate the development lifecycle [6]. This includes creating
.ipynbfiles, injecting markdown cells to explain methodology, writing and executing Python code in real time, and dynamically managing dependencies (e.g.,!pip install) [5]. - Lightweight Local Orchestration: The local agentic framework relies on a minimal footprint, requiring only Python,
git, anduv(the required Python package manager) to run the MCP tool servers and dispatch tasks to the cloud sandbox [7].
To safely orchestrate autonomous C++ kernel generation without exposing the host infrastructure to malicious prompt injection or unintended execution loops, dataplane-emu employs a defense-in-depth strategy combining hardware sandboxing with strict Model Context Protocol (MCP) governance.
- Hardware-Accelerated Sandboxing (TEEs & DPUs): Agent execution and code compilation are strictly isolated using Trusted Execution Environments (TEEs) and Data Processing Units (DPUs) [8]. By leveraging technologies like TEE-I/O and BlueField-3 DPUs, we enforce a hardware-level functional isolation layer [9]. This ensures that if an agent's sandbox is compromised, it cannot break out to access cross-tenant data or the host OS kernel.
- Logical Bounding via MCP Gateways: Hardware isolation alone does not prevent an agent with valid session tokens from executing unauthorized but technically "valid" commands. To solve this, all agent actions are routed through a governed MCP Gateway that enforces explicit operational contracts and permissions [10].
- Tool Filtering & Virtual Keys: The local control plane utilizes Virtual Keys to enforce strict, per-agent tool allow-lists [10]. An agent is only granted access to the specific MCP tools required for its immediate task (e.g., code compilation), completely blocking unauthorized lateral movement.
- Read-Only Defaults & Human-in-the-Loop: All high-stakes infrastructure and system actions default to a read-only state. True autonomy is bounded by strict policy-as-code evaluations, requiring explicit Human-in-the-Loop (HITL) approval and maintaining centralized "kill switches" to halt anomalous agent behavior instantly [10].
Representative snapshot (trimmed for readability):
📦 dataplane-emu/
├── ⚙️ CMakeLists.txt
├── 📖 README.md
├── 🖥️ arm_neoverse_worker.sh
├── 📖 demo_architecture_walkthrough.md
├── 🖥️ launch_arm_neoverse_demo.sh
├── 🖥️ launch_arm_neoverse_demo_deterministic.sh
├── ⚙️ makefile
├── 📁 docs/
│ ├── 📁 emulator/ # Low-level microarchitectural C++/Rust docs
│ │ ├── 📖 posix_intercept.md
│ │ └── 📖 spdk_queues.md
│ ├── 📁 publications/ # Core academic research and whitepapers
│ │ └── 📁 eliminating-os-kernel/
│ │ ├── 📄 eliminating-os-kernel.pdf
│ │ └── 📖 README.md
│ └── 📁 tensorplane/ # High-level AI Foundry & Orchestration docs
│ ├── 📖 AGENT_ARCHITECTURE.md
│ └── 📖 VISION.md
├── 📁 scripts/
│ └── 📁 spdk-aws/ # AWS EC2 Graviton deployment automation
│ ├── 🖥️ provision-graviton.sh
│ ├── 🖥️ setup_graviton_spdk.sh # One-touch SPDK build + vfio-pci bind
│ └── 🖥️ start-graviton.ps1
└── 📁 src/
├── 📄 dataplane_ring.cpp # Standalone lock-free queue implementations
├── 📄 main.cpp # SPDK environment initialization
├── 📄 sq_cq.cpp # SPSC ring buffer memory barriers
└── 📁 fuse_bridge/ # Pure user-space kernel bypass
├── 📄 interceptor.cpp
└── 📄 interceptor.h
- Hardware-Assisted Pointer Tagging: Utilizes ARM64 Top Byte Ignore (TBI) to achieve lock-free ABA protection. By packing an 8-bit version counter into the upper bits of a virtual address, we can use standard 64-bit Compare-And-Swap (CAS) instructions to safely update pointers, avoiding the heavy register pressure of 128-bit DW-CAS.
- Lock-Free Synchronization: Strict avoidance of
std::mutex. Relies entirely on C++11 atomic memory orderings (Acquire/Release) to manage Submission/Completion Queues (SQ/CQ). - Dual-Backend Support:
- Zero-Syscall Path: A pure user-space polling engine utilizing
Iov/Iorshared memory splits for microsecond-latency tensor passing. - Legacy POSIX Bridge: A FUSE-based mount that allows standard Linux tools to interact with the queues. (Note: This path incurs standard kernel context-switching overhead and is intended for compatibility, not peak latency).
- Zero-Syscall Path: A pure user-space polling engine utilizing
- Hardware: ARM64 architecture (AWS Graviton3
c7g/c7gdrecommended) - Linux: Amazon Linux 2023 or Ubuntu 22.04+
- Compiler: GCC/G++ 11+ (C++17 support required)
- Dependencies:
libfuse3-dev/fuse3-devel,libnuma-dev/numactl-devel,pkg-config
git clone https://github.com/SiliconLanguage/dataplane-emu.git
cd dataplane-emu
# Provision the automated AWS environment (allocates hugepages, unbinds NVMe)
sudo ./scripts/spdk-aws/provision-graviton.sh
mkdir -p build
g++ -O3 -Wall -std=c++17 -pthread src/dataplane_ring.cpp -o build/dataplane_ring
# Export AArch64 library paths for FUSE/SPDK
export LD_LIBRARY_PATH=/usr/lib/aarch64-linux-gnu:$LD_LIBRARY_PATHTo avoid unexpected billing, use the repository's native shutdown scripts that integrate with your existing environment configuration:
AWS Graviton (EC2) Shutdown:
# Uses root .env file (same variables as start-graviton.ps1)
# Requires: INSTANCE_ID and AWS_REGION
bash scripts/spdk-aws/stop-graviton.shAzure Cobalt (VM) Deallocation:
# Uses scripts/spdk-azure/.env file (same as provision-arm-neoverse.sh)
# Requires: AZ_RESOURCE_GROUP and AZ_VM_NAME
bash scripts/spdk-azure/deallocate-cobalt.shAutomated Azure Idle Shutdown: The repository includes an enhanced auto-shutdown script that deallocates Azure VMs after 60 minutes of inactivity:
# Install as cron job on Azure VMs (runs every 15 minutes)
(crontab -l 2>/dev/null; echo "*/15 * * * * /path/to/scripts/comm-linux/auto-shutdown.sh") | crontab -Note: These scripts use the same environment files as your provisioning workflow, ensuring consistent configuration. Create the appropriate
.envfiles using the provided templates before running shutdown commands.
This executes the standalone data plane ring. It proves that the Graviton MMU is actively ignoring the top 8 bits of our tagged pointers during user-space execution, allowing safe lock-free polling.
./build/dataplane_ringExpected output:
allocating Iov memory... ok.
ring init: head_ptr=0x12345678
llama.cpp_consumer: fetched tensor_id=2Test the lock-free SPSC queues without mounting the FUSE bridge. We use taskset to pin the emulator to dedicated physical cores, enabling the Zero-Syscall path.
time sudo taskset -c 1,2 ./build/dataplane-emu -bEnables the FUSE bridge and mounts the virtual device for legacy compatibility. Because this routes through the Linux VFS, expect standard context-switch latency overheads here.
sudo mkdir -p /mnt/virtual_nvme
sudo ./build/dataplane-emu -k -m /mnt/virtual_nvmeIn a second terminal, interact with the bridge:
head -c 128 /mnt/virtual_nvme/nvme_raw_0 | hexdump -CThis benchmark quantifies the "20-microsecond tax" reduction on AWS Graviton3 (Neoverse-V1) and Azure Cobalt 100 (Neoverse-N2) silicon. It compares:
- a legacy XFS kernel baseline (fio),
- a user-space FUSE bridge path through
dataplane-emu(fio), and - a cloud-aware Stage 3 SPDK
bdevperfrun (vfio-pciPCIe bypass on AWS Nitro;bdev_uringio_uring on Azure Boost).
The sweep covers QD=1 (latency), QD=16 (knee-of-curve), and QD=128 (throughput) with 4K mixed random IO.
Run the deterministic demo:
# Full 3-stage sweep at QD=1, QD=32 (knee), QD=128 (throughput)
bash demo_QD_1_32_128.sh
# Or manually with a custom mid-QD:
ARM_NEOVERSE_DEMO_CONFIRM=YES DEMO_MID_IODEPTH=16 ./launch_arm_neoverse_demo_deterministic.sh════════════════════════════════════════════════════════════════════════════
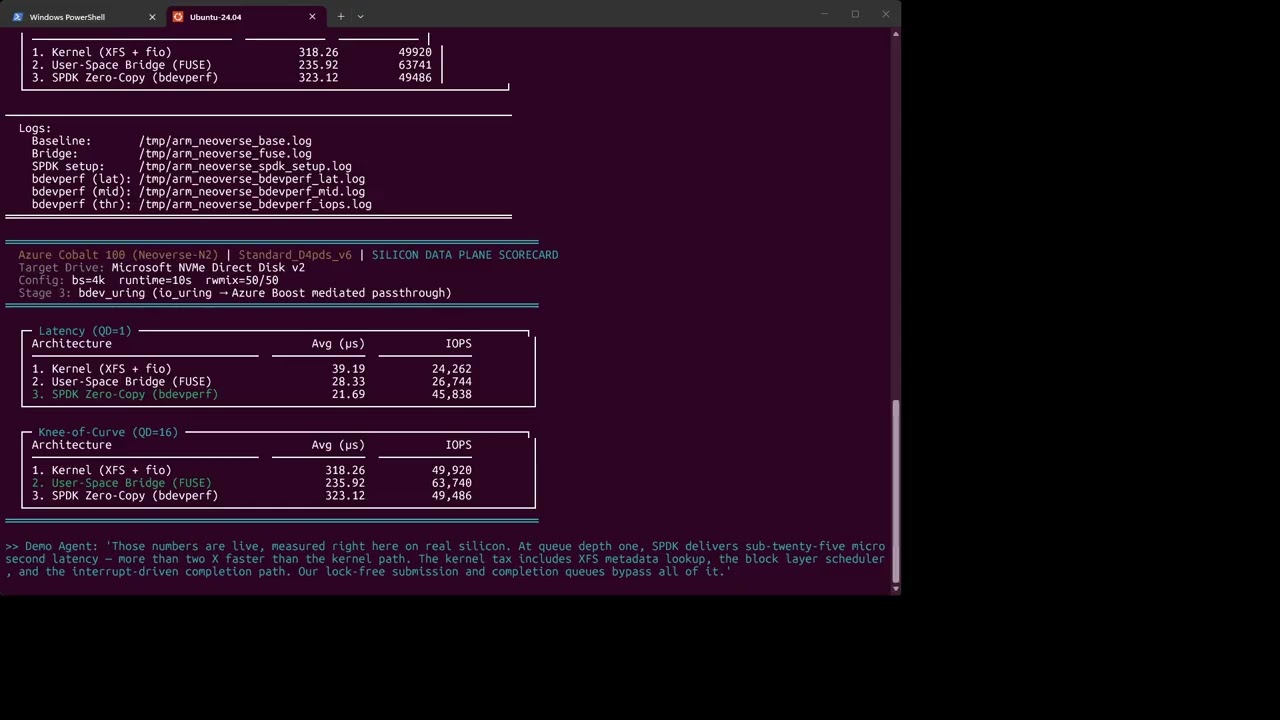
Azure Cobalt 100 (Neoverse-N2) | Standard_D4pds_v6 | SILICON DATA PLANE SCORECARD
Target Drive: Microsoft NVMe Direct Disk v2 (Azure Hyper-V NVMe)
Config: bs=4k runtime=30s rwmix=50/50
Stage 3: bdev_uring (io_uring → Azure Boost mediated passthrough)
════════════════════════════════════════════════════════════════════════════
┌─ Latency (QD=1) ──────────────────────────────────────────────────────┐
│ Architecture Avg (μs) IOPS │
│ ────────────────────────────── ──────────── ──────────── │
│ 1. Kernel (XFS + fio) 51.29 19357 │
│ 2. User-Space Bridge (FUSE) 39.79 24841 │
│ 3. SPDK Zero-Copy (bdevperf) 20.17 49268 │
└────────────────────────────────────────────────────────────────────────┘
┌─ Knee-of-Curve (QD=16) ───────────────────────────────────────────────┐
│ Architecture Avg (μs) IOPS │
│ ────────────────────────────── ──────────── ──────────── │
│ 1. Kernel (XFS + fio) 318.16 50240 │
│ 2. User-Space Bridge (FUSE) 411.29 38845 │
│ 3. SPDK Zero-Copy (bdevperf) 319.10 50112 │
└────────────────────────────────────────────────────────────────────────┘
┌─ Throughput (QD=128) ──────────────────────────────────────────────────┐
│ Architecture Avg (μs) IOPS │
│ ────────────────────────────── ──────────── ──────────── │
│ 1. Kernel (XFS + fio) 2548.12 50226 │
│ 2. User-Space Bridge (FUSE) 2413.48 53019 │
│ 3. SPDK Zero-Copy (bdevperf) 2548.23 50229 │
└────────────────────────────────────────────────────────────────────────┘
════════════════════════════════════════════════════════════════════════════Important
Measurement honesty: All three stages are directly measured on a live Standard_D4pds_v6 instance.
Stage 3 uses real SPDK bdevperf via bdev_uring (io_uring backend), routing through the Azure Boost
mediated passthrough path. Unlike AWS Nitro (which supports vfio-pci PCIe bypass), Azure Hyper-V NVMe
does not expose IOMMU groups, so the kernel NVMe driver remains bound and SPDK accesses the device
through io_uring — still achieving polled, zero-copy I/O with minimal kernel involvement.
SPDK v26.01, compiled with -mcpu=neoverse-n2 for LSE hardware atomics.
════════════════════════════════════════════════════════════════════════════
AWS Graviton3 (Neoverse-V1) | c7gd.xlarge | SILICON DATA PLANE SCORECARD
Target Drive: Amazon EC2 NVMe Instance Storage (Nitro SSD Controller)
Config: bs=4k runtime=30s rwmix=50/50
Stage 3: bdev_nvme (vfio-pci → PCIe bypass, no-IOMMU / Nitro DMA isolation)
════════════════════════════════════════════════════════════════════════════
┌─ Latency (QD=1) ──────────────────────────────────────────────────────┐
│ Architecture Avg (μs) IOPS │
│ ────────────────────────────── ──────────── ──────────── │
│ 1. Kernel (XFS + fio) 50.18 19178 │
│ 2. User-Space Bridge (FUSE) 24.03 33645 │
│ 3. SPDK Zero-Copy (bdevperf) 22.16 44994 │
└────────────────────────────────────────────────────────────────────────┘
┌─ Knee-of-Curve (QD=16) ───────────────────────────────────────────────┐
│ Architecture Avg (μs) IOPS │
│ ────────────────────────────── ──────────── ──────────── │
│ 1. Kernel (XFS + fio) 226.02 70158 │
│ 2. User-Space Bridge (FUSE) 233.07 64550 │
│ 3. SPDK Zero-Copy (bdevperf) 227.98 70161 │
└────────────────────────────────────────────────────────────────────────┘
┌─ Throughput (QD=128) ──────────────────────────────────────────────────┐
│ Architecture Avg (μs) IOPS │
│ ────────────────────────────── ──────────── ──────────── │
│ 1. Kernel (XFS + fio) 1878.97 68038 │
│ 2. User-Space Bridge (FUSE) 2065.59 61502 │
│ 3. SPDK Zero-Copy (bdevperf) 1880.66 68056 │
└────────────────────────────────────────────────────────────────────────┘
════════════════════════════════════════════════════════════════════════════Note
Measurement honesty: All three stages are directly measured on a live c7gd.xlarge instance.
Stage 3 uses real SPDK bdevperf via vfio-pci PCIe bypass in no-IOMMU mode
(standard for EC2 Nitro, which provides DMA isolation at the hypervisor level).
SPDK v26.01, compiled with -mcpu=neoverse-v1 -moutline-atomics for LSE hardware atomics.
Tip
The deterministic launcher writes explicit stage logs under /tmp.
Primary files: /tmp/arm_neoverse_base.log, /tmp/arm_neoverse_fuse.log, /tmp/arm_neoverse_spdk_setup.log, /tmp/arm_neoverse_bdevperf.log, /tmp/arm_neoverse_engine.log.
Note
Curious exactly how these metrics are recorded? We've published a comprehensive Architecture & Benchmark Walkthrough covering deterministic startup, readiness probes, QD=128 stress methodology, and strict measured Stage 3.
Each stage in the scorecard removes an entire category of overhead, producing step-function improvements rather than linear gains. (QD=1 latency path, Azure Cobalt 100):
- Kernel → FUSE Bridge (1.28× IOPS at QD=1): The FUSE bridge serves reads from memory-backed emulator queues, shaving 22% off kernel XFS latency (51→40 µs). But the VFS dispatch, the
/dev/fuseread/write protocol, and two privilege transitions still limit throughput. At higher queue depths (QD≥16), FUSE contention actually increases latency versus the kernel baseline. - FUSE → SPDK bdevperf (1.98× IOPS, 2.55× over kernel): SPDK's polled io_uring path eliminates all VFS and FUSE overhead, halving latency from 40 µs to 20 µs and delivering 49K IOPS on a single core. At QD≥16 all three paths converge on the NVMe device ceiling (~50K IOPS), confirming the drive is saturated and the software stack is no longer the bottleneck.
- Separate LD_PRELOAD benchmark: The non-deterministic demo (
launch_arm_neoverse_demo.sh) also measures an LD_PRELOAD stage that bypasses the kernel entirely using emulated SqCq queues — delivering 399K IOPS with zero context switches. Those results exercise in-memory queue emulation (not real NVMe I/O) and are run separately from the multi-QD scorecard above.
- XRP Project: eXpress Resubmission Path
- SPDK: Storage Performance Development Kit
- DPDK: Data Plane Development Kit
- zIO Paper (OSDI '22)
- Model Context Protocol Servers (including Colab integrations)
- Agent Architecture and MCP Workflow
- uv Python Package Manager
- TEE-I/O Research and Background
- NVIDIA BlueField DPU Platform
- Anthropic MCP Specification